机器学习笔记
序言
这次准备跟着斯坦福CS229进行机器学习的学习,想着之前有看过吴恩达老师的课程讲解,但是没有动过手,因此了解还是比较模糊,希望这次能够多动手来理解,然后我朋友还推荐了224n和224w,打算等着这个基础看完再去学习。另我学长推荐了林轩田,但我看推导公式的时候有些迷糊,打算也许之后再看看?
本篇是我自己的学习记录,如果对你有所帮助就是我最大的快乐,那么话不多说,一起进入学习吧!
注意
由于要在博客里显示图片,对md文件里面的图片进行了路径的修改,即,现在的路径为:
原因就是hexo的读取图片的路径和typora不一致,我们需要在typora文字编辑界面中把图片路径从 同名文件夹\imagename 修改为 imagename 。可以直接使用typora 的Ctrl+F 进行全局替换,将路径前缀替换为空即可。若想获取原路径只需添上去掉的路径名即可
CS229
第一部分 线性回归(linear regression)
线性回归也许是最简单的学习算法之一。
咱们先来聊几个使用监督学习来解决问题的实例。假如咱们有一个数据集,里面的数据是俄勒冈州波特兰市的
套房屋的面积和价格:
| 居住面积(平方英尺) | 价格(千美元) |
|---|---|
用这些数据来投个图:
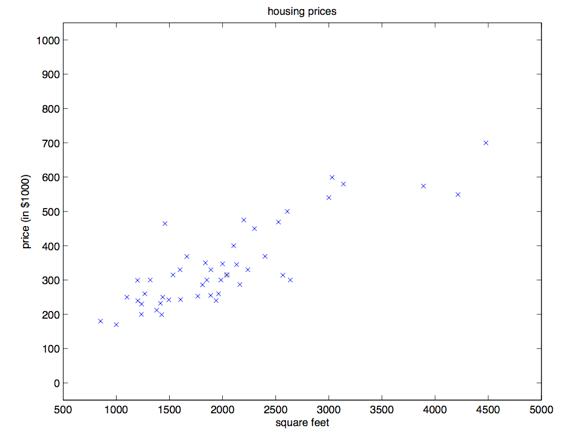
有了这样的数据,我们怎样才能学会预测波特兰其他房屋的价格,以及它们的居住面积?
这里要先规范一下符号和含义,这些符号以后还要用到,咱们假设
表示 “输入的” 变量值(在这个例子中就是房屋面积),也可以叫做输入特征;然后咱们用
来表示“输出值”,或者称之为目标变量,这个例子里面就是房屋价格。这样的一对
就称为一组训练样本,然后咱们用来让机器来学习的数据集,就是——一个长度为
的训练样本的列表
——也叫做一个训练集。另外一定注意,这里的上标
来表示 输入值的空间,大写的
表示输出值的空间。在本节的这个例子中,输入输出的空间都是实数域,所以
然后再用更加规范的方式来描述一下监督学习问题,我们的目标是,给定一个训练集,来让机器学习一个函数
,让
是一个与对应的真实
值比较接近的评估值。由于一些历史上的原因,这个函数
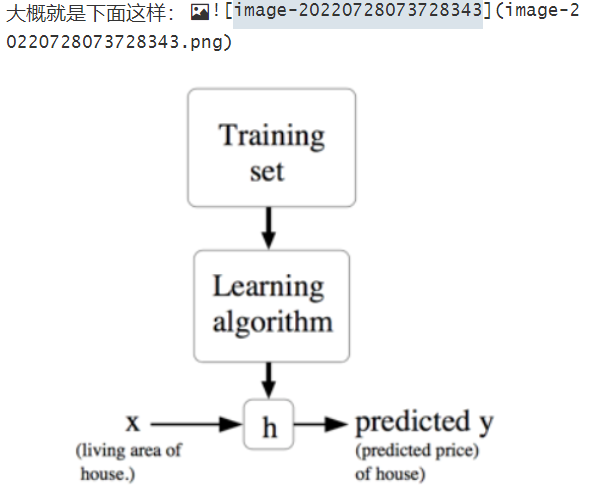
就被叫做假设(hypothesis)。用一个图来表示的话,这个过程大概就是下面这样: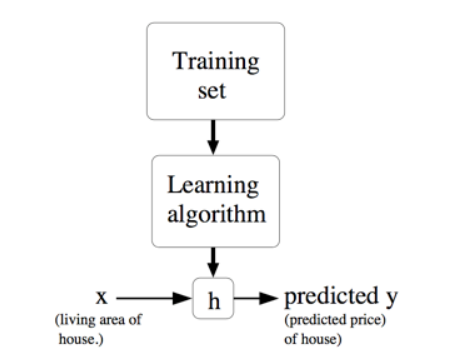
如果我们要预测的目标变量是连续的,比如在咱们这个房屋价格-面积的案例中,这种学习问题就被称为回归问题。 如果
只能取一小部分的离散的值(比如给定房屋面积,咱们要来确定这个房子是一个住宅还是公寓),这样的问题就叫做分类问题。
现在回到问题:
为了让我们的房屋案例更有意思,咱们稍微对数据集进行一下补充,增加上每一个房屋的卧室数目:
| 居住面积(平方英尺) | 卧室数目 | 价格(千美元) |
|---|---|---|
现在,输入特征
就是在
范围取值的一个二维向量了。例如
就是训练集中第
个房屋的面积,而
就是训练集中第
个房屋的卧室数目。(通常来说,设计一个学习算法的时候,选择哪些输入特征都取决于你,你完全可以选择包含其他的特征,例如房屋是否有壁炉,卫生间的数量啊等等。关于特征筛选的内容会在后面的章节进行更详细的介绍,不过目前来说就暂时先用给定的这两个特征了。)
要进行这个监督学习,咱们必须得确定好如何在计算机里面对这个函数/假设
进行表示。咱们现在刚刚开始,就来个简单点的,咱们把
为变量的线性函数:
这里的
是参数(也可以叫做权重),是从
到
的线性函数映射的空间参数。在不至于引起混淆的情况下,咱们可以把
里面的
省略掉,就简写成
。另外为了简化公式,咱们还设
(这个为 截距项 intercept term)。这样简化之后就有了:
等式最右边的
和
都是向量,等式中的
是输入变量的个数(不包括
)。
现在,给定了一个训练集,咱们怎么来挑选/学习参数
呢?一个看上去比较合理的方法就是让
尽量逼近
,至少对咱已有的训练样本能适用。用公式的方式来表示的话,就要定义一个函数,来衡量对于每个不同的
值,
与对应的
的距离。这样用如下的方式定义了一个 成本函数 (cost function):
1. 梯度下降—-最小均方算法(LMS algorithm)
我们希望选择一个能让
最小的
值。怎么做呢,咱们先用一个搜索的算法,从某一个对
的“初始猜测值”,然后对
值不断进行调整,来让
逐渐变小,最好是直到我们能够达到一个使
最小的
。具体来说,咱们可以考虑使用梯度下降法(gradient descent algorithm),这个方法就是从某一个
的初始值开始,然后逐渐重复更新:
(上面的这个更新要同时对应从
到
的所有
值进行。)这里的
也称为学习速率。这个算法是很自然的,逐步重复朝向
降低最快的方向移动。
本文中 := 表示的是计算机程序中的一种赋值操作,是把等号右边的计算结果赋值给左边的变量,a := b$就表示用 b 的值覆盖原有的a值。
如果写的是 a == b 则表示的是判断二者相等的关系。
要实现这个算法,咱们需要解决等号右边的导数项。首先来解决只有一组训练样本
的情况,这样就可以忽略掉等号右边对
的求和项目了。公式就简化下面这样:
当只有一个训练样本的时候,我们推导出了 LMS 规则。当一个训练集有超过一个训练样本的时候,有两种对这个规则的修改方法。第一种就是下面这个算法:
读者很容易能证明,在上面这个更新规则中求和项的值就是
(这是因为对
的原始定义)。所以这个更新规则实际上就是对原始的成本函数
进行简单的梯度下降。这一方法在每一个步长内检查所有整个训练集中的所有样本,也叫做批量梯度下降法(batch gradient descent)。这里要注意,因为梯度下降法容易被局部最小值影响,而我们要解决的这个线性回归的优化问题只能有一个全局的而不是局部的最优解;因此,梯度下降法应该总是收敛到全局最小值(假设学习速率
不设置的过大)。
很明确是一个凸二次函数。下面是一个样例,其中对一个二次函数使用了梯度下降法来找到最小值。
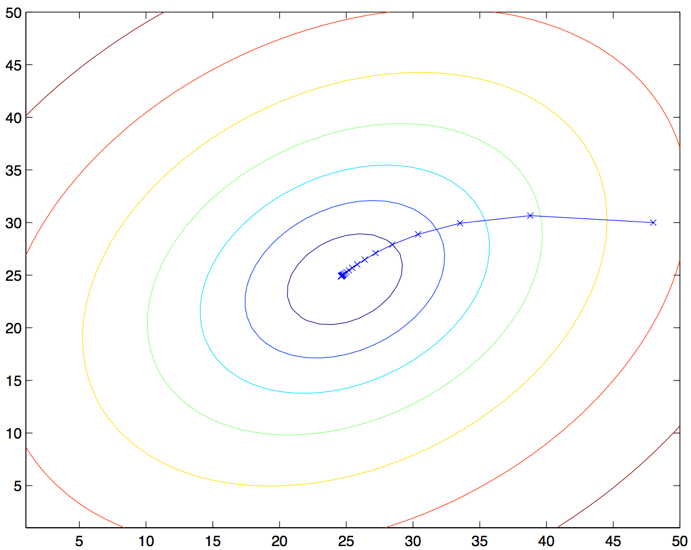
上图的椭圆就是一个二次函数的轮廓图。图中还有梯度下降法生成的规矩,初始点位置在
。图中的画的
(用直线连接起来了)标记了梯度下降法所经过的
的可用值。
对咱们之前的房屋数据集进行批量梯度下降来拟合
,把房屋价格当作房屋面积的函数来进行预测,我们得到的结果是
。如果把
作为一个定义域在
上的函数来投影,同时也投上训练集中的已有数据点,会得到下面这幅图:
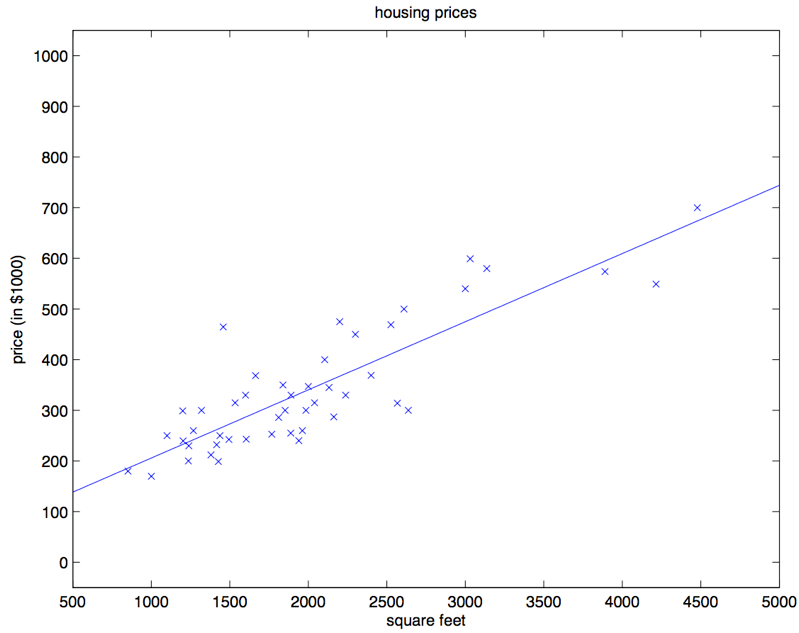
如果在数据集中添加上卧室数目作为输入特征,那么得到的结果就是
这个结果就是用批量梯度下降法来获得的。此外还有另外一种方法能够替代批量梯度下降法,这种方法效果也不错。如下所示
在这个算法里,我们对整个训练集进行了循环遍历,每次遇到一个训练样本,根据每个单一训练样本的误差梯度来对参数进行更新。这个算法叫做随机梯度下降法(stochastic gradient descent),或者叫增量梯度下降法(incremental gradient descent)。批量梯度下降法要在运行第一步之前先对整个训练集进行扫描遍历,当训练集的规模
变得很大的时候,引起的性能开销就很不划算了;随机梯度下降法就没有这个问题,而是可以立即开始,对查询到的每个样本都进行运算。通常情况下,随机梯度下降法查找到足够接近最低值的
的速度要比批量梯度下降法更快一些。(也要注意,也有可能会一直无法收敛(converge)到最小值,这时候
会一直在
最小值附近震荡;不过通常情况下在最小值附近的这些值大多数其实也足够逼近了,足以满足咱们的精度要求,所以也可以用。由于这些原因,特别是在训练集很大的情况下,随机梯度下降往往比批量梯度下降更受青睐。
当然更常见的情况通常是我们事先对数据集已经有了描述,并且有了一个确定的学习速率
,然后来运行随机梯度下降,同时逐渐让学习速率
随着算法的运行而逐渐趋于
,这样也能保证我们最后得到的参数会收敛到最小值,而不是在最小值范围进行震荡。
译者注:由于以上种种原因,通常更推荐使用的都是随机梯度下降法,而不是批量梯度下降法,尤其是在训练用的数据集规模大的时候。)
2. 法方程(The normal equations)
这种方法寻找起来简单明了,而且不需要使用迭代算法。这种方法就是,我们直接利用找对应导数为 0 位置的
,这样就能找到
的最小值了。我们想实现这个目的,还不想写一大堆代数公式或者好几页的矩阵积分,所以就要介绍一些做矩阵积分的记号。
2.1 矩阵导数
假如有一个函数
从
大小的矩阵映射到实数域,那么就可以定义当矩阵为
如下所示:
因此,这个梯度
本身也是一个
的矩阵,其中的第
个元素是
。
假如
是一个
矩阵,然后给定的函数
为:
这里面的
表示的意思是矩阵
的第
个元素。然后就有了梯度:
$$
\nabla A f(A) =\begin{bmatrix} \frac 32 & 10A{12} \ A_{22} & A_{21} \ \end{bmatrix}
$$
然后咱们还要引入
求迹运算,简写为
。对于一个给定的 n x n 方形矩阵 A,它的迹定义为对角项和:
假如 a 是一个实数,实际上 a 就可以看做是一个 1 x 1 的矩阵,那么就有 a 的迹 tr a = a。(如果你之前没有见到过这个“运算记号”,就可以把 A 的迹看成是 tr(A),或者理解成为一个对矩阵 A$进行操作的 trace 函数。不过通常情况都是写成不带括号的形式更多一些。)
如果有两个矩阵 A 和B,能够满足 AB为方阵,trace 求迹运算就有一个特殊的性质: trAB = trBA (自己想办法证明)。在此基础上进行推论,就能得到类似下面这样的等式关系:
下面这些和求迹运算相关的等量关系也很容易证明。其中 A 和 B 都是方形矩阵,a 是一个实数:
接下来咱们就来在不进行证明的情况下提出一些矩阵导数(其中的一些直到本节末尾才用得上)。另外要注意等式(4)中的A必须是非奇异方阵(non-singular square matrices),而 |A| 表示的是矩阵 A的行列式。那么我们就有下面这些等量关系:
2.2 最小二乘法回顾(Least squares revisited)
接下来咱们就继续用逼近模型(closed-form)来找到能让
最小的
值。首先咱们把
用矩阵-向量的记号来重新表述。
给定一个训练集,把设计矩阵(design matrix)
设置为一个
矩阵(实际上,如果考虑到截距项,也就是
那一项,就应该是
矩阵),这个矩阵里面包含了训练样本的输入值作为每一行:
然后,咱们设
是一个
维向量(m-dimensional vector),其中包含了训练集中的所有目标值:
因为
,所以可以证明存在下面这种等量关系:
对于向量
,则有
,因此利用这个性质,可以推出:
最后,要让
的值最小,就要找到函数对于
导数。结合等式(2)和等式(3),就能得到下面这个等式(5):
因此就有:
在第三步,我们用到了一个定理,也就是一个实数的迹就是这个实数本身;第四步用到了
这个定理;第五步用到了等式(5),其中
,还用到了等式 (1)。要让 J取得最小值,就设导数为 0 ,然后就得到了下面的法线方程(normal equations):
所以让
取值最小的
就是
3. 概率解释
在面对回归问题的时候,可能有这样一些疑问,就是为什么选择线性回归,尤其是为什么选择最小二乘法作为成本函数
?在本节里,我们会给出一系列的概率基本假设,基于这些假设,就可以推出最小二乘法回归是一种非常自然的算法。
首先咱们假设目标变量和输入值存在下面这种等量关系:
上式中
是误差项,用于存放由于建模所忽略的变量导致的效果 (比如可能某些特征对于房价的影响很明显,但我们做回归的时候忽略掉了)或者随机的噪音信息(random noise)。进一步假设
是独立同分布的 (IID ,independently and identically distributed) ,服从高斯分布(Gaussian distribution ,也叫正态分布 Normal distribution),其平均值为
,方差(variance)为
。这样就可以把这个假设写成
。然后
的密度函数就是:
这意味着存在下面的等量关系:
这里的记号
表示的是这是一个对于给定
时
的分布,用
代表该分布的参数。 注意这里不能用
来当做条件,因为
并不是一个随机变量。这个
的分布还可以写成
。
给定一个设计矩阵(design matrix)
,其包含了所有的
,然后再给定
,那么
的分布是什么?数据的概率以
的形式给出。在
取某个固定值的情况下,这个等式通常可以看做是一个
的函数(也可以看成是
的函数)。当我们要把它当做
的函数的时候,就称它为 似然函数(likelihood function)
结合之前对
的独立性假设 (这里对
以及给定的
也都做同样假设),就可以把上面这个等式改写成下面的形式:
现在,给定了
和
之间关系的概率模型了,用什么方法来选择咱们对参数
的最佳猜测呢?最大似然法(maximum likelihood)告诉我们要选择能让数据的似然函数尽可能大的
。也就是说,咱们要找的
能够让函数
取到最大值。
除了找到
最大值,我们还以对任何严格递增的
的函数求最大值。如果我们不直接使用
,而是使用对数函数,来找对数似然函数
的最大值,那这样对于求导来说就简单了一些:
$$
\begin{aligned}
l(\theta) &=\log L(\theta)\
&=\log \prod ^m _{i=1} \frac 1{\sqrt{2\pi}\sigma} exp(- \frac {(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2})\
&= \sum ^m {i=1}log \frac 1{\sqrt{2\pi}\sigma} exp(- \frac {(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2})\
&= m \log \frac 1{\sqrt{2\pi}\sigma}- \frac 1{\sigma^2}\cdot \frac 12 \sum^m{i=1} (y^{(i)}-\theta^Tx^{(i)})^2\
\end{aligned}
$$
因此,对
取得最大值也就意味着下面这个子式取到最小值:
到这里我们能发现这个子式实际上就是
,也就是最原始的最小二乘成本函数(least-squares cost function)。
总结一下也就是:在对数据进行概率假设的基础上,最小二乘回归得到的
和最大似然法估计的
是一致的。所以这是一系列的假设,其前提是认为最小二乘回归(least-squares regression)能够被判定为一种非常自然的方法,这种方法正好就进行了最大似然估计(maximum likelihood estimation)。(要注意,对于验证最小二乘法是否为一个良好并且合理的过程来说,这些概率假设并不是必须的,此外可能(也确实)有其他的自然假设能够用来评判最小二乘方法。)
另外还要注意,在刚才的讨论中,我们最终对
,而且也确实在不知道
的情况下就已经找到了结果。稍后我们还要对这个情况加以利用,到时候我们会讨论指数族以及广义线性模型。
4. 局部加权线性回归(Locally weighted linear regression)
假如问题还是根据从实数域内取值的
来预测
。左下角的图显示了使用
来对一个数据集进行拟合。我们明显能看出来这个数据的趋势并不是一条严格的直线,所以用直线进行的拟合就不是好的方法。

那么这次不用直线,而增加一个二次项,用
来拟合。(看中间的图) 很明显,我们对特征补充得越多,效果就越好。不过,增加太多特征也会造成危险的:最右边的图就是使用了五次多项式
来进行拟合。看图就能发现,虽然这个拟合曲线完美地通过了所有当前数据集中的数据,但我们明显不能认为这个曲线是一个合适的预测工具,比如针对不同的居住面积
来预测房屋价格
。先不说这些特殊名词的正规定义,咱们就简单说,最左边的图像就是一个欠拟合(under fitting) 的例子,比如明显能看出拟合的模型漏掉了数据集中的结构信息;而最右边的图像就是一个过拟合(over fitting) 的例子。(在本课程的后续部分中,当我们讨论到关于学习理论的时候,会给出这些概念的标准定义,也会给出拟合程度对于一个猜测的好坏检验的意义。)
正如前文谈到的,也正如上面这个例子展示的,一个学习算法要保证能良好运行,特征的选择是非常重要的。(等到我们讲模型选择的时候,还会看到一些算法能够自动来选择一个良好的特征集。)在本节,咱们就简要地讲一下局部加权线性回归(locally weighted linear regression ,缩写为LWR),这个方法是假设有足够多的训练数据,对不太重要的特征进行一些筛选。这部分内容会比较简略,因为在作业中要求学生自己去探索一下LWR 算法的各种性质了。
在原始版本的线性回归算法中,要对一个查询点
进行预测,比如要衡量
,要经过下面的步骤:
使用参数
进行拟合,让数据集中的值与拟合算出的值的差值平方
最小(最小二乘法的思想);输出
。
相应地,在 LWR 局部加权线性回归方法中,步骤如下:
使用参数
进行拟合,让加权距离
最小;输出
。
上面式子中的
是非负的权值。直观点说就是,如果对应某个
的权值
特别大,那么在选择拟合参数
的时候,就要尽量让这一点的
最小。而如果权值
特别小,那么这一点对应的
就基本在拟合过程中忽略掉了。
对于权值的选取可以使用下面这个比较标准的公式:
4 如果
是有值的向量,那就要对上面的式子进行泛化,得到的是
,或者:
,这就看是选择用
还是
。
要注意的是,权值是依赖每个特定的点
的,而这些点正是我们要去进行预测评估的点。此外,如果
非常小,那么权值
就接近 1;反之如果
非常大,那么权值
就变小。所以可以看出,
的选择过程中,查询点
附近的训练样本有更高得多的权值。(
is chosen giving a much higher “weight” to the (errors on) training examples close to the query point x.)(还要注意,当权值的方程的形式跟高斯分布的密度函数比较接近的时候,权值和高斯分布并没有什么直接联系,尤其是当权值不是随机值,且呈现正态分布或者其他形式分布的时候。)随着点
到**查询点 **
的距离降低,训练样本的权值的也在降低,参数
控制了这个降低的速度;
也叫做带宽参数,这个也是在你的作业中需要来体验和尝试的一个参数。
局部加权线性回归是咱们接触的第一个非参数 算法。而更早之前咱们看到的无权重的线性回归算法就是一种参数 学习算法,因为有固定的有限个数的参数(也就是
),这些参数用来拟合数据。我们对
进行了拟合之后,就把它们存了起来,也就不需要再保留训练数据样本来进行更进一步的预测了。与之相反,如果用局部加权线性回归算法,我们就必须一直保留着整个训练集。这里的非参数算法中的 非参数“non-parametric” 是粗略地指:为了呈现出假设
随着数据集规模的增长而线性增长,我们需要以一定顺序保存一些数据的规模。(The term “non-parametric” (roughly) refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis h grows linearly with the size of the training set. )
第二部分 分类和逻辑回归(Classification and logistic regression)
分类问题其实和回归问题很像,只不过我们现在要来预测的
的值只局限于少数的若干个离散值。眼下咱们首先关注的是二值化分类 问题,也就是说咱们要判断的
只有两个取值,0 或者 1。(咱们这里谈到的大部分内容也都可以扩展到多种类的情况。)例如,假如要建立一个垃圾邮件筛选器,那么就可以用
表示一个邮件中的若干特征,然后如果这个邮件是垃圾邮件,y 就设为1,否则 y$为 0。0也可以被称为消极类别(negative class),而 1就成为积极类别(positive class),有的情况下也分别表示成“-” 和 “+”。对于给定的一个
,对应的
也称为训练样本的标签(label)。
1. 逻辑回归
改变一下假设函数
的形式,来解决这个问题。比如咱们可以选择下面这个函数:
其中有:
这个函数叫做逻辑函数 (Logistic function) ,或者也叫双弯曲S型函数(sigmoid function)。下图是
的函数图像:

当
的时候
趋向于
,而当
时
趋向于
。此外,这里的这个
,也就是
,是一直在 0
那么,给定了逻辑回归模型了,咱们怎么去拟合一个合适的
呢?我们之前已经看到了在一系列假设的前提下,最小二乘法回归可以通过最大似然估计来推出,那么接下来就给我们的这个分类模型做一系列的统计学假设,然后用最大似然法来拟合参数吧。
首先假设:
更简洁的写法是:
假设 m个训练样本都是各自独立生成的,那么就可以按如下的方式来写参数的似然函数:
然后还是跟之前一样,取个对数就更容易计算最大值:
怎么让似然函数最大?就跟之前咱们在线性回归的时候用了求导数的方法类似,咱们这次就是用梯度上升法(gradient ascent)。还是写成向量的形式,然后进行更新,也就是
。 (注意更新方程中用的是加号而不是减号,因为我们现在是在找一个函数的最大值,而不是找最小值了。) 还是先从只有一组训练样本
上面的式子里,我们用到了对函数求导的定理
。然后就得到了随机梯度上升规则:
如果跟之前的 LMS 更新规则相对比,就能发现看上去挺相似的;不过这并不是同一个算法,因为这里的
现在定义成了一个
的非线性函数。尽管如此,我们面对不同的学习问题使用了不同的算法,却得到了看上去一样的更新规则,这个还是有点让人吃惊。这是一个巧合么,还是背后有更深层次的原因呢?在我们学到了 GLM 广义线性模型的时候就会得到答案了。(另外也可以看一下 习题集1 里面 Q3 的附加题。)
2. 让
再回到用 S 型函数
来进行逻辑回归的情况,咱们来讲一个让
取最大值的另一个算法。
开始之前,咱们先想一下求一个方程零点的牛顿法。假如我们有一个从实数到实数的函数
,然后要找到一个
,来满足
,其中
是一个实数。牛顿法就是对
进行如下的更新:
这个方法可以通过一个很自然的解释,我们可以把它理解成用一个线性函数来对函数
进行逼近,这条直线是
的切线,而猜测值是
,解的方法就是找到线性方程等于零的点,把这一个零点作为
设置给下一次猜测,然后以此类推。
下面是对牛顿法的图解:

在最左边的图里面,可以看到函数
就是沿着
的一条直线。这时候是想要找一个
来让
。这时候发现这个
值大概在 1.3 左右。加入咱们猜测的初始值设定为
。牛顿法就是在
这个位置画一条切线(中间的图)。这样就给出了下一个
猜测值的位置,也就是这个切线的零点,大概是2.8。最右面的图中的是再运行一次这个迭代产生的结果,这时候
大概是1.8。就这样几次迭代之后,很快就能接近
。
牛顿法的给出的解决思路是让
。如果咱们要用它来让函数
取得最大值能不能行呢?函数
等于零的点。所以通过令
,咱们就可以同样用牛顿法来找到
的最大值,然后得到下面的更新规则:
(扩展一下,额外再思考一下: 如果咱们要用牛顿法来求一个函数的最小值而不是最大值,该怎么修改?)译者注:试试法线的零点
最后,在咱们的逻辑回归背景中,
是一个有值的向量,所以我们要对牛顿法进行扩展来适应这个情况。牛顿法进行扩展到多维情况,也叫牛顿-拉普森法(Newton-Raphson method),如下所示:
上面这个式子中的
和之前的样例中的类似,是关于
的偏导数向量;而
是一个
矩阵 ,实际上如果包含截距项的话,应该是,
,也叫做 Hessian, 其详细定义是:
牛顿法通常都能比(批量)梯度下降法收敛得更快,而且达到最小值所需要的迭代次数也低很多。然而,牛顿法中的单次迭代往往要比梯度下降法的单步耗费更多的性能开销,因为要查找和转换一个
的 Hessian 矩阵;不过只要这个
不是太大,牛顿法通常就还是更快一些。当用牛顿法来在逻辑回归中求似然函数
的最大值的时候,得到这一结果的方法也叫做Fisher评分(Fisher scoring)。
3. 感知器学习算法(The perceptron learning algorithm)
设想一下,对逻辑回归方法修改一下,“强迫”它输出的值要么是 0 要么是 1。要实现这个目的,很自然就应该把函数 g的定义修改一下,改成一个阈值函数(threshold function):
如果我们还像之前一样令
,但用刚刚上面的阈值函数作为 g 的定义,然后如果我们用了下面的更新规则:
这样我们就得到了感知器学习算法。
在 1960 年代,这个“感知器(perceptron)”被认为是对大脑中单个神经元工作方法的一个粗略建模。鉴于这个算法的简单程度,这个算法也是我们后续在本课程中讲学习理论的时候的起点。但一定要注意,虽然这个感知器学习算法可能看上去表面上跟我们之前讲的其他算法挺相似,但实际上这是一个和逻辑回归以及最小二乘线性回归等算法在种类上都完全不同的算法;尤其重要的是,很难对感知器的预测赋予有意义的概率解释,也很难作为一种最大似然估计算法来推出感知器学习算法。
第三部分 广义线性模型(Generalized Linear Models)
1. 指数族 (The exponential family)
在学习 GLMs 之前,我们要先定义一下指数组分布(exponential family distributions)。如果一个分布(概率密度函数)能用下面的方式来写出来,我们就说这类分布属于指数族:
上面的式子中,
叫做此分布的自然参数 (natural parameter,也叫典范参数 canonical parameter) ;
叫做充分统计量(sufficient statistic) ,我们目前用的这些分布中通常
;而
是一个对数分割函数(log partition function)。
这个量本质上扮演了归一化常数(normalization constant)的角色,也就是确保
的总和或者积分等于1。
当给定
时,就定义了一个用
进行参数化的分布族(family,或者叫集 set);通过改变
,我们就能得到这个分布族中的不同分布。
现在咱们看到的伯努利(Bernoulli)分布和高斯(Gaussian)分布就都属于指数分布族。伯努利分布的均值是
,也写作
,确定的分布是
,因此有
。这时候只要修改
,就能得到一系列不同均值的伯努利分布了。现在我们展示的通过修改
,而得到的这种伯努利分布,就属于指数分布族;也就是说,只要给定一组
,就可以用上面的等式(6)来确定一组特定的伯努利分布了。
我们这样来写伯努利分布:
因此,自然参数(natural parameter)就给出了,即
。 很有趣的是,如果我们翻转这个定义,用
来解
就会得到
。这正好就是之前我们刚刚见到过的 **S型函数(sigmoid function)**!在我们把逻辑回归作为一种广义线性模型(GLM)的时候还会得到:
上面这组式子就表明了伯努利分布可以写成等式
。
接下来就看看高斯分布吧。还记得吧,在推导线性回归的时候,
的值对我们最终选择的
和
都没有影响。所以我们可以给
取一个任意值。为了简化推导过程,就令
。然后就有了下面的等式:
如果我们把
留作一个变量,高斯分布就也可以表达成指数分布的形式,其中
就是一个二维向量,同时依赖
和
。然而,对于广义线性模型GLMs方面的用途,
参数也可以看成是对指数分布族的更泛化的定义:
。这里面的
叫做分散度参数(dispersion parameter),对于高斯分布,
;不过上文中我们已经进行了简化,所以针对我们要考虑的各种案例,就不需要再进行更加泛化的定义了。这样,我们就可以看出来高斯分布是属于指数分布族的,可以写成下面这样:
指数分布族里面还有很多其他的分布:
- 例如多项式分布(multinomial),这个稍后我们会看到;
- 泊松分布(Poisson),用于对计数类数据进行建模,后面再问题集里面也会看到;
- 伽马和指数分布(the gamma and the exponential),这个用于对连续的、非负的随机变量进行建模,例如时间间隔;
- 贝塔和狄利克雷分布(the beta and the Dirichlet),这个是用于概率的分布;
- 还有很多,这里就不一一列举了。
在下一节里面,我们就来讲一讲对于建模的一个更通用的“方案”,其中的
(给定
)可以是上面这些分布中的任意一种。
2. 构建广义线性模型(Constructing GLMs)
设想你要构建一个模型,来估计在给定的某个小时内来到你商店的顾客人数(或者是你的网站的页面访问次数),基于某些确定的特征
,例如商店的促销、最近的广告、天气、今天周几啊等等。我们已经知道泊松分布(Poisson distribution)通常能适合用来对访客数目进行建模。知道了这个之后,怎么来建立一个模型来解决咱们这个具体问题呢?非常幸运的是,泊松分布是属于指数分布族的一个分布,所以我们可以对该问题使用广义线性模型(Generalized Linear Model,缩写为 GLM)。在本节,我们讲一种对刚刚这类问题构建广义线性模型的方法。
进一步泛化,设想一个分类或者回归问题,要预测一些随机变量
的值,作为
的一个函数。要导出适用于这个问题的广义线性模型,就要对我们的模型、给定
下
的条件分布来做出以下三个假设:
,即给定
的分布属于指数分布族,是一个参数为
的指数分布。——假设1给定
,目的是要预测对应这个给定
的期望值。咱们的例子中绝大部分情况都是
,这也就意味着我们的学习假设
输出的预测值
要满足
。 (注意,这个假设通过对
的选择而满足,在逻辑回归和线性回归中都是如此。例如在逻辑回归中,
。译者注:这里的
应该就是对给定x时的y值的期望的意思。)——假设2自然参数
和输入值
是线性相关的,
,或者如果
是有值的向量,则有
。——假设3上面的几个假设中,第三个可能看上去证明得最差,所以也更适合把这第三个假设看作是一个我们在设计广义线性模型时候的一种 “设计选择 design choice”,而不是一个假设。那么这三个假设/设计,就可以用来推导出一个非常合适的学习算法类别,也就是广义线性模型 GLMs,这个模型有很多特别友好又理想的性质,比如很容易学习。此外,这类模型对一些关于
的分布的不同类型建模来说通常效率都很高;例如,我们下面就将要简单介绍一些逻辑回归以及普通最小二乘法这两者如何作为广义线性模型来推出。
1. 普通最小二乘法(Ordinary Least Squares)
普通最小二乘法实际上是广义线性模型中的一种特例,设想如下的背景设置:目标变量
(在广义线性模型的术语也叫做响应变量response variable)是连续的,然后我们将给定
的
的分布以高斯分布
来建模,其中
可以是依赖
的一个函数。这样,我们就让上面的
分布成为了一个高斯分布。在前面内容中我们提到过,在把高斯分布写成指数分布族的分布的时候,有
。所以就能得到下面的等式:
第一行的等式是基于假设2;第二个等式是基于定理当
,则
的期望就是
;第三个等式是基于假设1,以及之前我们此前将高斯分布写成指数族分布的时候推导出来的性质
;最后一个等式就是基于假设3。
2. 逻辑回归(Logistic Regression)
这里咱们还是看看二值化分类问题,也就是
。给定了
是一个二选一的值,那么很自然就选择伯努利分布(Bernoulli distribution)来对给定 x 的 y 的分布进行建模了。在我们把伯努利分布写成一种指数族分布的时候,有
。另外还要注意的是,如果有
,那么
。所以就跟刚刚推导普通最小二乘法的过程类似,有以下等式:
所以,上面的等式就给了给了假设函数的形式:
。如果你之前好奇咱们是怎么想出来逻辑回归的函数为
,这个就是一种解答:一旦我们假设以 x 为条件的 y 的分布是伯努利分布,那么根据广义线性模型和指数分布族的定义,就会得出这个式子。
再解释一点术语,这里给出分布均值的函数 g 是一个关于自然参数的函数,
,这个函数也叫做规范响应函数(canonical response function), 它的反函数
叫做规范链接函数(canonical link function)。 因此,对于高斯分布来说,它的规范响应函数正好就是识别函数(identify function);而对于伯努利分布来说,它的规范响应函数则是逻辑函数(logistic function)。
7 很多教科书用 g 表示链接函数,而用反函数
来表示响应函数;但是咱们这里用的是反过来的,这是继承了早期的机器学习中的用法,我们这样使用和后续的其他课程能够更好地衔接起来。
3. Softmax 回归
咱们再来看一个广义线性模型的例子吧。设想有这样的一个分类问题,其中响应变量 y 的取值可以是 k 个值当中的任意一个,也就是
。例如,我们这次要进行的分类就比把邮件分成垃圾邮件和正常邮件两类这种二值化分类要更加复杂一些,比如可能是要分成三类,例如垃圾邮件、个人邮件、工作相关邮件。这样响应变量依然还是离散的,但取值就不只有两个了。因此咱们就用多项式分布(multinomial distribution)来进行建模。
下面咱们就通过这种多项式分布来推出一个广义线性模型。要实现这一目的,首先还是要把多项式分布也用指数族分布来进行描述。
要对一个可能有 k 个不同输出值的多项式进行参数化,就可以用 k 个参数
来对应各自输出值的概率。不过这么多参数可能太多了,形式上也太麻烦,他们也未必都是互相独立的(比如对于任意一个
中的值来说,只要知道其他的
个值,就能知道这最后一个了,因为总和等于1,也就是
)。所以咱们就去掉一个参数,只用 k-1 个:
来对多项式进行参数化,其中
$$
\phi_i = p (y = i; \phi),p (y = k; \phi) = 1 −\sum ^{k−1}{i=1}\phi i
\phi_k = 1 − \sum_{i=1}^{k−1} \phi_i
$$
,但一定要注意,这个并不是一个参数,而是完全由其他的 k-1个参数来确定的。
要把一个多项式表达成为指数组分布,还要按照下面的方式定义一个
:
这次和之前的样例都不一样了,就是不再有 T(y) = y;然后,T(y) 现在是一个 k – 1 维的向量,而不是一个实数了。向量 T(y)中的第 i 个元素写成
。
现在介绍一种非常有用的记号。指示函数(indicator function)
,如果参数为真,则等于1;反之则等于0(
)。例如
, 而
。所以我们可以把T(y) 和 y 的关系写成
。(往下继续阅读之前,一定要确保你理解了这里的表达式为真!)在此基础上,就有了
。
现在一切就绪,可以把多项式写成指数族分布了。写出来如下所示:
$$
\begin{aligned}
p(y;\phi) &=\phi_1^{1{y=1}}\phi_2^{1{y=2}}\dots \phi_k^{1{y=k}} \
&=\phi_1^{1{y=1}}\phi_2^{1{y=2}}\dots \phi_k^{1-\sum_{i=1}^{k-1}1{y=i}} \
&=\phi_1^{(T(y))_1}\phi_2^{(T(y))2}\dots \phi_k^{1-\sum{i=1}^{k-1}(T(y))_i } \
&=exp((T(y))_1 log(\phi_1)+(T(y))2 log(\phi_2)+\dots+(1-\sum{i=1}^{k-1}(T(y))_i)log(\phi_k)) \
&= exp((T(y))1 log(\frac{\phi_1}{\phi_k})+(T(y))2 log(\frac{\phi_2}{\phi_k})+\dots+(T(y)){k-1}log(\frac{\phi{k-1}}{\phi_k})+log(\phi_k)) \
&=b(y)exp(\eta^T T(y)-a(\eta))
\end{aligned}
$$
其中:
这样咱们就把多项式方程作为一个指数族分布来写了出来
与
对应的链接函数为:
为了方便起见,我们再定义
。对链接函数取反函数然后推导出响应函数,就得到了下面的等式:
这就说明了
,然后可以把这个关系代入回到等式(7),这样就得到了响应函数:
上面这个函数从
映射到了
,称为 Softmax 函数。
要完成我们的建模,还要用到前文提到的假设3,也就是
是一个 x 的线性函数。所以就有了
,其中的
就是我们建模的参数。为了表述方便,我们这里还是定义
,这样就有
,跟前文提到的相符。因此,我们的模型假设了给定 x 的 y 的条件分布为:
这个适用于解决
的分类问题的模型,就叫做 Softmax 回归。 这种回归是对逻辑回归的一种扩展泛化。
假设(hypothesis) h 则如下所示:
也就是说,我们的假设函数会对每一个
,给出
概率的估计值。(虽然咱们在前面假设的这个
只有
维,但很明显
可以通过用
减去其他所有项目概率的和来得到,即
)
最后,咱们再来讲一下参数拟合。和我们之前对普通最小二乘线性回归和逻辑回归的原始推导类似,如果咱们有一个有 m 个训练样本的训练集
,然后要研究这个模型的参数
,我们可以先写出其似然函数的对数:
要得到上面等式的第二行,要用到等式(8)中的设定
。现在就可以通过对
取最大值得到的
而得到对参数的最大似然估计,使用的方法就可以用梯度上升法或者牛顿法了。
p5





